The Pillars of K4 - An Overview
By Mathias Ball
Applications that collect searchable data (basically every messenger) usually use a SQLite database. SQLite is a very simple relational SQL database without any procedural programming capabilities. Datacentric applications, even those which use far more advanced database products, often view a database as a simple data storage container from which data can be retrieved very fast. If no attempt is made to use relational features, a database often is reduced to a centralized data store, used by some orthogonal persistence layer which is fed data by some middleware. This scenario probably is the most popular one today. A three tier application, where a middleware analyzes, organizes and manages all data, stores it into a database - which kind often is not even important - or provides it to a graphical user interface. The middleware owns the business logic.
The Database: Firebird
With K4 we use an entirely different approach. Relational database products originally aimed to provide complete solutions to any business requirements. Therefore, most products provide powerful procedural programming capabilities - although in face of the market dominance of middleware applications they fell a bit into oblivion. However, since we know of the possibilities our approach is focused on using a relational database as means to organize the data and to implement business logic using relational logic and procedural language in a quite unique way. Therefore, the first pillar of our solution we chose Firebird as a database using PSQL as a language respectively.
Why did we decide to go that way?
- We wanted to store all content in the database, searchable.
- A well crafted relational DB can provide really good performance when searching things. We wanted to profit from this as much as possible. And as it seems we do.
- All relations between entities are enforced by the database. The relations between entities are cast into well defined database structures too, so the database can not only enforce things, but also evaluate them. There is no external middleware. The database is the solely foundation for the entire application.
- A relational database provides a number of tools to enforce structure and rules. This is very much what we want. Based on this we designed an architecture for K4 which makes heavy use of predefined modular building blocks as well as rules allowing us to translate real world entities into data structures quite efficiently. Using relational structures and specifically indices in a smart way really helps achieve order and speed at the same time.
- A further benefit of the approach: When we are designing a structure for a new entity, we are really forced to understand the entity. We have to decide: Which data are really important for that entity? What should be searchable? What is additional information? What is needed to the things we put into the database in its original form?
- Without any question: Avoiding a three tiered is a question of choice. But one thing is for sure. With the power of a fully developed relational DB at your hands you get so many things for free that you soon realize that the K4-approach makes a lot of things a lot easier to handle.
The Process Manager: PM
PSQL delivers powerful tools to make use of enhanced database capabilities, but a database by nature of its design is a passive, standalone software component. It can not reach out and fetch e-mail from an IMAP server. To be able to do such things we created a separate tool which we call PM. The name PM originally comes from the term “process manager”, since it was thought to be a tool to initiate transactions in the database. Essentially it is the external manager of all things which are prepared to go on in the database. Additionaly, it analyses external entity data, breaks it down into database structures and provides it to the database. On request it is able to communicate things which are prepared by the database to the outside world. For instance, it can format and send an e-mail, if the database has prepared one. PM is entirely written in Python - a very powerful programming environment. PM is the second pillar of the K4 architecture. It handles:
- Database management functions (creation, backup, restore, migration).
- By the means of PM, the database is “surrounded” by a living cloud of predefined processes (like satellites), which perform tasks for the database. For instance, a process may be polling an IMAP mailbox for new e-mail. It fetches e-mails, parses them and calls the interface PSQL functions to put all e-mail data into the database.
- Data post-processing: When an e-mail is fetched, its attachments are analyzed for their content and all the words it contains are collected. This word list is provided to the database and logically linked to the e-mail object to allow to find this e-mail by search terms later on.
- Communication: A specialized process waits for e-mails to be sent. It extracts e-mail data from the database, creates a standardized e-mail-text-object and negotiates with an SMTP server to send the e-mail.
- Database process management: When a transaction in the database processes things, it may require to start a follow-up transaction. But this something a database can not initiate by itself. Instead it is dependent on external help. PM provides exactly that by catching a signal for a job from the database and initiating an upcoming transaction as required.
- Meta-processes: Meaning bigger tasks, as for instance reading in an entire e-mail folder from an e-mail-program like Thunderbird at once, reading all files from a specified folder, converting them to K4 database documents, importing vCards, importing book entries from a Tellico database (Tellico is a tool to manage collections), reading additional information from internet resources (for instance CDDB, Wiki), reading history files from messengers.
- The process system is fully configurable and modularized.
The Graphical User Interface: Clarissa
While having your data organized in a DB and having them fetched from, sent to and organized by a process management sytem is all well and good, as a user you will need a graphical user interface (GUI) to interact with your data. The GUI is a desktop application and represents the final pillar of the K4 architecture. It is named Clarissa and is written in Lazarus (Object-Pascal). Our requirements for Clarissa are: Easy to install - Easy to use - Easy to understand. For Clarissa we use a very generic approach. The application does not know any details about the data it presents or which you enter. All the intelligence how to handle the data are known to the database - and to some degree PM - only. Clarissa only cares about presenting data to you as well as letting you enter data comfortably and to search and link data together very easily. You as the user can further restrict results by filtering and ordering them. Furthermore Clarissa provides a powerful search system reminding of a web search, which enables you to search all kinds of things you have stored by search terms.
Technically this means that a set of data which you can see on any form are the direct result of a query to the database transformed to a visual representation. To achieve this generic datasets initiate database queries which deliver all the results that are available. The GUI is built from building blocks which are configured via JSON-files.
The Principle of Interaction
The following picture illustrates the operation of the K4 system based on how its pillar components interact. The arrows in the picture display the communication lines between the GUI and the database as well as the database and PM processes.
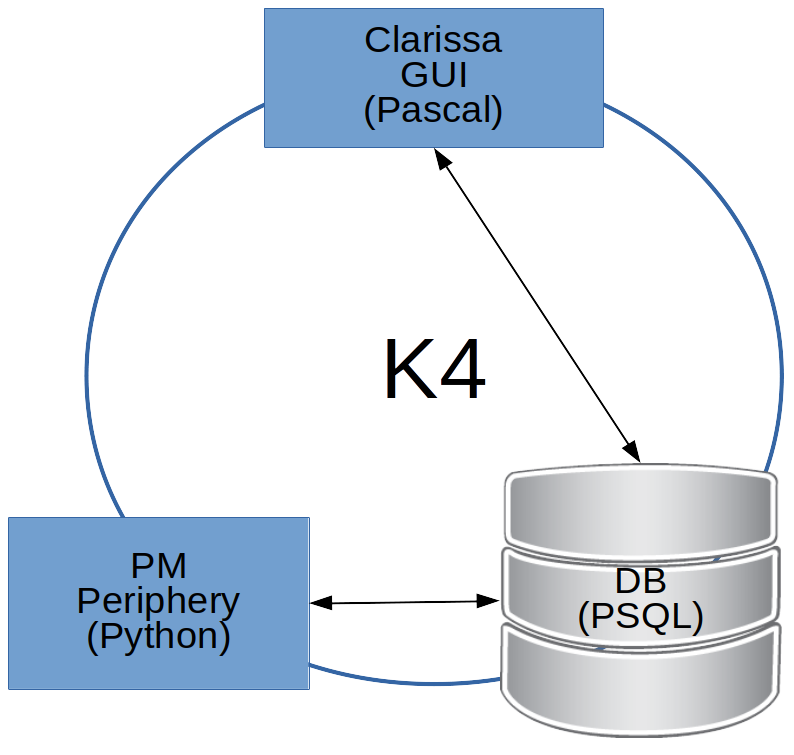
The K4 concept is a variant of the Model-View-Controller paradigm which is known from GUI software design. “Model” is realized in the database pillar. The Model in our case is built on “entities” or “real world things”. The “Controller” is realized by PM, handling import, export and processing of entity data. The Clarissa-GUI is the K4-equivalent of the “View” on the data.