Tiny Data - Wie verwalte ich meine Daten intelligent?
By Mathias Ball
Titelseite
Tiny Data… Oder wie verwalte ich meine Daten intelligent?
Bevor wir uns mit den Einzelheiten beschäftigen, möchte ich kurz umreißen, weshalb ich diesen - zugegeben - provokanten Titel gewählt habe.
Zunächst einmal: Wir leben heute in einer schrillen Zeit, in der man sich provokanter Schlagzeilen bedienen muß, um wahrgenommen zu werden. Dennoch ist das nicht mein Anliegen.
In diesem Zusammenhang möchte ich anstelle einer Agenda ein Zitat anbringen…
Zitat
Nicht das Viele erfüllt, sondern das Wesentliche. Bert Hellinger
Wieso?
Unser Titel spielt kritisch auf zwei Modeworte in der heutigen IT-Welt an: “KI” und “Big Data”. Kein Magazin geht mehr über den Ladentisch ohne einen Artikel darüber. Spekulanten wittern große Geschäfte und selbst die Bundesregierung erwartet, daß unser Land eine Vorreiterrolle einnimmt. Und schließlich, auch dieser Linuxtag steht unter diesem Motto. Wenn man all diese Meldungen verfolgt, kann man sich des Eindrucks nicht verwehren, daß wir als Menschen im Digitalen - trotz DSGVO - keinerlei Privatsphäre mehr haben, kommerziellen Interessen ausgeliefert sind und auch sonst im Arbeitsleben immer überflüssiger werden.
Aber lassen Sie mich kurz zwei Dinge, eine aktuelles Forschungsprogramm und eine persönliche Geschichte, einschieben:
Erstens: Im Rahmen meiner Arbeit recherchiere ich gelegentlich verschiedene Raumfahrtprojekte. Eines davon ist das ESA Projekt GAIA - Globales Astrometrisches Interferometer für die Astrophysik - einen Satelliten, der über mehrere Jahre hinweg den gesamten Himmel optisch abtastet und Positionen von Himmelskörpern ermittelt. Der Detektor besteht aus 106 CCDs und umfaßt insgesamt etwa eine Milliarde Pixel. Jetzt stellen Sie sich vor, Sie wollten alle Bildinformationen aufheben! Es ist undenkbar. Die Schöpfer von GAIA mußten von Anfang an die Datenmenge so weit reduzieren, daß sie auch übertragen werden kann. Und ich meine damit keine Kompressionsverfahren, sondern echte Reduktion der Daten, d.h. Sie werfen Inhalte weg. Ich möchte damit andeuten: Alles aufzuheben (Big Data Ansatz) ist oft nicht praktikabel; ich meine sogar, in den allermeisten Fällen. Warum bringe ich gerade dieses Projekt? Es zeigt am Beispiel sehr deutlich, wie man sich zuerst Gedanken darüber macht: Welche Informationen sind für mich wesentlich?
Zweitens: Mein Abitur absolvierte ich noch vor dem Fall der Mauer im Osten Berlins. Wir hatten das Privileg einer der damaligen Rechenzentren in Zossen zu besuchen. Man stelle sich das vor! Mit Rechnern waren hier Schränke gemeint, wo große Magnetbänder spulten, die Monitore hatten kleine grüne Bildröhren und die Tastaturen erinnerten eher an Pausenbrotverpackungen. Mit viel Enthusiasmus erläuterte unsere Führung die Programmiersprache Logo am Beispiel von Vererbung, also A ist Vater von B und der wiederum Vater von C, dann ist C Enkelsohn von A… Und so weiter und so fort. Allen von Technik begeisterten Schülern stand die Begeisterung ins Gesicht geschrieben, als wie beinahe in magischer Manier der Rechner intelligent erschien, indem er aus grundlegendem Basiswissen gewisse Schlüsse zu ziehen vermochte wie eben: C ist Enkelsohn von A. Die Vorführung schloß mit einer gewissen Prophezeihung: “In 20 Jahren haben wir künstliche Intelligenz.”
Wow! Daran mußte ich teilhaben!
Das war 1988! Heute, 31 Jahre später, erlebe ich persönlich ein deja vu, wenn es heißt “künstliche Intelligenz”. Lochkarten und Magnetbänder sind längst nur noch Staub absorbierende Relikte in Museen, die ganze Enzyklopedia Britannica paßt auf ein Medium, kaum größer als ein Fingernagel, Videos kann man in Echtzeit encodieren und weltweit übertragen und die Rechengeschwindigkeit schafft in Sekunden, woran Generationen von Mathematikern über Jahrhunderte knobelten. Zweifellos kann heute Rechentechnik Atemberaubendes leisten. Dennoch bleibt das Training neuronaler Netze ein Bollwerk aus Matrizenoperationen. Ist das Intelligenz? Eine gute Frage!
Um das zu beantworten, müssen wir zunächst klären, was ist eigentlich gemeint mit “künstlicher Intelligenz”?
Ich möchte keine philosophische Abhandlung beginnen, dennoch sollten wir unser Augenmerk kurz darauf lenken, was “Intelligenz” eigentlich meint. Dafür lohnt sich ein Blick in die Wikipedia, dort ist etwas zum Ursprung des Wortes geschrieben. Es stammt aus dem Lateinischen und bedeutet “verstehen”, wörtlich “wählen zwischen”. Das heißt, wir reden über Erkenntnisvermögen. Jetzt kann sich jeder zwei Fragen stellen: Ist ein neuronales Netz zu Erkenntnis fähig? Und, wenn man ein neuronales Netz aufsetzt und trainiert, woher bezieht es seine “künstliche Intelligenz”? Ganz klar: Aus seinem Strukturdesign und aus den Trainingsdaten. Und woher stammen diese Dinge? Von dem, der vor dem Rechner sitzt!
Also: Die eigentliche Intelligenz, die auf eine Maschine übertragen wird, geht vom Schöpfer des Programms, des neuronalen Netzes aus. Wir als Programmierer sind es, die dem System “Fähigkeiten” einhauchen, die es intelligent erscheinen lassen. Genau genommen tut das jedes Programm, nicht nur ein neuronales Netz.
Genau das meint unser Titel: Wie verwalte ich meine Daten intelligent? Mit Betonung auf “Ich”.
Das Intro unseres Titels “Tiny Data” spielt auf den zweiten Modebegriff “Big Data” an. Doch das einzige, was man diesem Begriff als Außenstehender ohne Spezialwissen entnehmen kann ist: Einen Sack voll Daten, unstrukturiert, Hauptsache aufgehoben… Und schließlich auch aufgeschoben.
Ich schließe nicht aus, daß manche Anwendungsfälle einen solchen Lösungsansatz rechtfertigen und sogar voraussetzen. Dennoch, es erscheint mir wesentlich sinnvoller, das Gegenteil zu bevorzugen, d.h. sich mit dem begnügen, was wirklich notwendig ist, denn…
Nicht das Viele erfüllt, sondern das Wesentliche.
Darum habe ich dieses Zitat zur Einstimmung gewählt!
Es stammt übrigens vom deutschen Buchautor Bert Hellinger, der sich als Psychoanalytiker und als “Familientherapeut” betätigte.
Und wer sind wir? Was bedeutet Database Driving Range?
Zunächst sind nur wir beide gemeint, wie auf der ersten Seite sichtbar. Rajko beschäftigt sich professionell mit Datenbanken, dort insbesondere mit Oracle. Ich habe mit Datenbanken beruflich wenig zu tun, doch sowohl in meiner Zeit als Astrophysiker als auch jetzt viel mit Softwareentwicklung.
Wir beide haben auf dem hiesigen Linuxtag vor drei Jahren schon einen Benchmark für Datenbanken vorgestellt. Jetzt ist es an der Zeit, erste Früchte unserer Arbeit, wo es eigentlich hingehen sollte, vorzustellen.
Alltägliche Probleme
Wozu beschäftigen wir uns mit Big oder Tiny Data, mit KI und, wie der Titel meines Vortrags verrät, mit persönlichen Daten? Gibt es da nicht schon genug Möglichkeiten? Viele gibt es sicher, aber betrachten wir zunächst einige Probleme aus dem Alltag, wie Sie sie sicher schon öfter erlebt haben.
Sie führen ein Gespräch mit Freunden, mit Kollegen, mit irgend jemanden. Wie oft ist es dabei vorgekommen, daß Sie sich rückbesinnen und folgende Frage durch Ihren Geist schimmert: Da war doch mal was? War das eine E-Mail, ein Dokument, eine Webseite oder was sonst? Wie finde ich das jetzt? Sie können sich der Kommandozeile bedienen, “find” und “grep” benutzen. Spätestens dann können Sie diese Werkzeuge vergessen, wenn Sie keine nativen Texte suchen. Ganz abgesehen davon: Die Suche dauert eine kleine Ewigkeit.
Warum ist Google erfolgreich? Man kann über den Konzern denken, was man will, aber Sie finden auf deren Seite relevantes Zeug! Auch wenn Sie sich vertippt haben. Die Trefferquote ist in den meisten Fällen hoch.
Damit das alles nicht nur Theorie bleibt, schon jetzt eine kurze Demonstration am Programm. Dazu habe ich bereits eine Datenbank angelegt und mit Inhalt gefüllt, sie soll uns hier als Modell dienen. Jetzt brauchen wir nur noch einen Suchbegriff. Ich bin der Ausbildung nach Physiker, und die haben i.d.R. zwei Favoriten: Einstein oder Heisenberg. Ich benutze für meine kurze Vorstellung den zweiten, da der gute Mann auch bekannt ist für seine Unschärferelation, die paßt ganz gut zum Thema der unscharfen Suche.
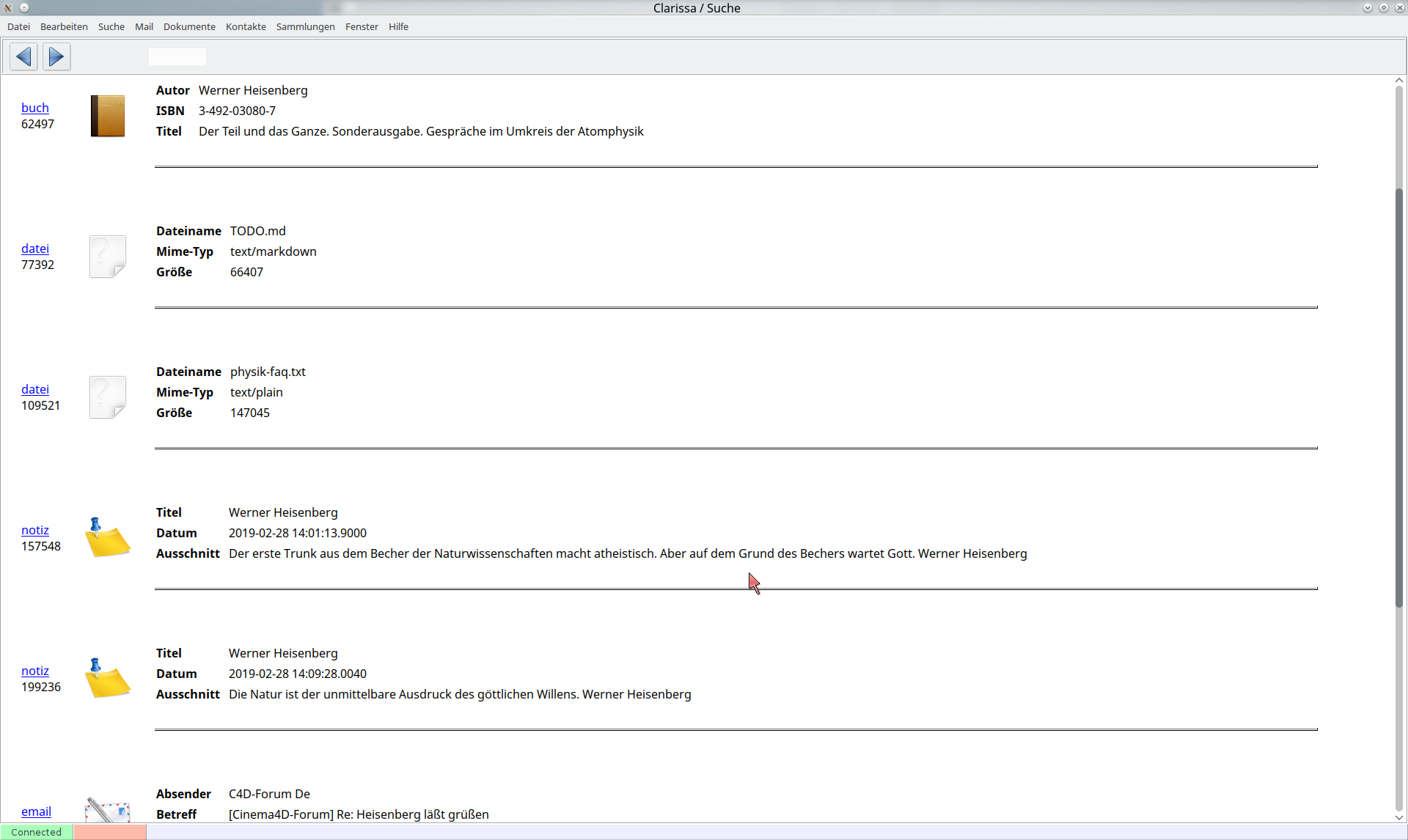
Was sehen wir?
Zunächst, es werden Daten unterschiedlichen Typs gefunden: Bücher, Dokumente, Notizen, E-Mails. Sie kennen sicherlich etliche Programme, die eine Suche anbieten, in den meisten Fällen sind es Programme, die zum Beispiel nur E-Mails verwalten, oder nur Dokumente.
Zweitens: Die Dinge in unserem Programm werden auch unabhängig von irgend welchen Ordnungsstrukturen (Ordner, Tags) gefunden, was bei Dateisystemen und oft auch bei Mailclients nicht der Fall ist. Viele Menschen haben mehrere E-Mail Accounts, und ihnen ist es egal, über welches Konto eine E-Mail eingetroffen ist.
Und drittens: Die Dinge werden schnell gefunden. Ich gestehe, die Datenbank ist noch nicht sonderlich groß, wir sprechen gegenwärtig von etwa 100 MB. Dennoch basieren unsere Bemühungen nicht umsonst auf einer SQL-Datenbank. Sie sind mit geeigneter Indizierung in der Lage, auch sehr große Datenmengen blitzschnell zu durchsuchen.
Doch weiter mit Themen aus dem Alltag: Sie finden eine Datei auf Ihrem Rechner und erinnern sich lediglich: Die habe ich vor Jahren bekommen. Sie erinnern sich aber nicht von wem. Kriegen Sie das raus? Mit einem gewöhnlichen Mailer artet das meistens in eine Suche nach der Stecknadel im Heuhaufen aus.
Und wenn Sie es schon gefunden haben, wer hat das noch empfangen? Wann? In welchem Zusammenhang? Womit hängt das Dokument noch zusammen? Alle von Ihnen, die mit einem Issue- bzw. Bugtracker arbeiten, werden das Problem kennen. Sie hängen Dateien an einzelne Bugs an. Wenn Sie einen Bug, d.h. dessen Nummer kennen, haben Sie auch die Anhänge. Können Sie sich das auch anders herum vorstellen?
Noch ein Beispiel aus der E-Mail Welt: Sie suchen überhaupt einen Anhang, eine ZIP Datei, eine EXE oder gar ein PDF-Dokument. Sie erinnern sich nur daran, worum es dabei ging und daß der Anhang ziemlich groß war. Würden Sie das heute in einer Sammlung E-Mails, die 10 Jahre umfaßt, wiederfinden?
Sie abonnieren Mailinglisten, haben bei irgendwelchen online Versandhändlern eingekauft, sind per Booking.com nach Syndey geflogen und kriegen nun sackweise Werbung am Tag, u.a. jede Woche ein neues Angebote für Sydney. Für mich ist es hilfreich, wenn ich weiß, wer mir wieviel Zeug sendet. Vielleicht kann ich so schnell ein paar lästigen Sendern den Saft abdrehen?
Verlassen wir einmal die inzwischen antiquierte Kommunikationsform E-Mail. Wer möchte, wenn schon etwas in den eigenen Daten gesucht wird, nicht über alles suchen, was persönliche Daten hergeben? Beispiel: Ich schreibe einen Artikel und sammle und verwalte dazu Informationen. Zum Thema will ich wissen, welche Bücher habe ich dazu, welche Webseiten abgelinkt, welche Kontakte kann ich dazu befragen und welche Unterhaltungen habe ich dazu schon geführt (also E-Mail Threads, Chats - wo auch immer)?
Anderes Beispiel, das mich persönlich eine Weile beschäftigte: Ahnenrecherchen. Sie haben parallel viele Anfragen bei Ämtern und Kirchen laufen, nebenbei recherchieren Sie online Stammbäume anderer Forscher, knüpfen Kontakte. Es gibt zwar Software, die Stammbäume und auch Quellen verwalten, aber keines unterstützt wirklich bei der Arbeit selbst. Auch hier gibt es E-Mails, Dokumente, Webseiten, Notizen und Sammlungen von Urkunden zusammenzuführen.
Die Liste könnte ich weiter fortführen. Sie sehen, es geht darum, ein Maximum an Informationen und Querverweisen aus den eigenen Daten herauszuholen, Arbeitsabläufe zu unterstützen. Es soll mehr sein, als nur einen Katalog der eigenen Bücher oder E-Mails; interessant werden die Daten erst, wenn sie in Verbindung zueinander gesetzt und effizient durchsucht werden können.
Sie werden feststellen, obwohl die Fragen trivial sind, daß es kaum bzw. keine Applikationen gibt, die das wirklich im gewünschten Umfang unterstützen.
Unser Projekt - K4
Aus den soeben formulierten Fragen, die wirklich nur einen winzigen Anteil dessen ausmachen, was uns vorschwebt, ergibt sich das Ziel, die Vision unseres Projekts K4.
Zunächst möchte ich ein paar der Ziele konkretisieren.
Der Begriff der Persönlichen Daten meint nicht nur Adressen und Namen einer Kontaktverwaltung sondern per se alles, was Sie selbst betrifft, egal ob es E-Mails sind, Chats, Bilder, eine Telefonrechnung oder der Steuerbescheid vom Finanzamt.
Erfassung: Das dürfte klar sein. Zunächst müssen die Daten aufbereitet werden. Wie ich am Anfang schon Wert darauf legte, wir wollen nicht pauschal alles in die Datenbank einleiten; sondern wir wollen gleich am Anfang der Verarbeitungskette wohl überlegt auswählen und strukturieren.
Wiedererkennung: Wenn ich ein Dokument auf der Festplatte in der Datenbank wiederfinden möchte, brauche ich einen Mechanismus, um sie zu erkennen. Hierbei geht es um die Verwaltung und Erzeugung von Hashes.
Redundanzfreiheit: E-Mail ist unter anderem deshalb antiquiert, weil es Anhänge beliebig vervielfältigt. Wenn man Anhänge (und ich meine hier die Inhalte, nicht die Dateinamen) identifizieren kann, kann man sie auch redundanzfrei speichern und dem frühzeitigen Platzen der Festplatte vorbeugen.
Integrität: Verwendet man sogar kryptographische Hashes wie SHA256, läßt sich auch sicherstellen, daß Dokumente, die von unserem System verwaltet werden, integer sind. Hier geht es nicht nur darum, Fälschungen zu erkennen, auch darum, zufällige Veränderungen zu bemerken. Ich habe selbst beruflich viel mit großen Bildmengen und Videos zu tun und öfter schon erlebt: Spontane Änderungen einzelner Bits (sogenannte Bitrots) werden immer spürbarer, je größer Festplatten sind. Darüber zerbrechen sich sogar die Programmierer von Dateisystemen, z.B. BTRFS, den Kopf.
Versionierung: Es ist sicher nicht der Zweck unseres Systems, GIT als Versionsverwaltungssystem abzulösen. Vielmehr dachten wir hier an eine einfache Möglichkeit, z.B. unterschiedliche Stände eines Artikels festzuhalten.
Sicherung, Migration: Das habe ich leider schon öfter erlebt, daß nach einem Umstieg auf eine neue Programmversion mühevoll eingegebenen Daten durcheinander geworfen sind. Sicherung und Migration erachten wir als eines unserer Kernthemen.
Vertraulich: Wer hat sich nicht schon einmal darüber mokiert, was man Firmen wie Google oder Facebook alles in den Rachen wirft? Ich bevorzuge den Gedanken, daß meine persönlichen Daten die Bezeichnung persönlich bzw. privat auch verdienen.
Erweiterbarkeit: Wenn ich schon Sammlungen anlegen kann, sei es zu eigenen Audiodateien, Bildern, Videos oder den Inhalt des eigenen Bücherschranks, dann möchte ich die Freiheit haben, auch ein beliebiges noch so exotisches Sammlungsobjekt zu verwalten. Briefmarken, Zinnfiguren, Modelleisenbahnen oder vielleicht auch Senfsorten. Nur zu!
Vernetzung: Ist als Idee für die Zukunft zu verstehen und bedient den Anspruch, daß persönliche Daten privat bleiben. Wenn ich schon tauschen möchte, dann direkt, ohne Instanz dazwischen.
Im Hinblick auf die Bedienung setzen wird uns weitere Zeile:
Einfachheit: Offen gestanden: Wer möchte heute noch E-Mails manuell sortieren? Oder umfangreiche Ordnungshierarchien anlegen?
Konsistenz: Gemeint ist inbesondere bei der Bedienung eines Programms. Das wird gerne unterschätzt.
Zentral: Meint hier nicht die zentrale Speicherung bei Dropbox oder Google, sondern ein Programm als Zentrale, als Anlaufstelle für den Benutzer.
Erreichbarkeit: Meint ein übersichtliches GUI-Design und eine substantielle Reduktion der Datenmenge mit wenigen Handgriffen.
Responsiv: MP3-Tags von 2000+ Audiodateien in 0,5s durchsuchen. Das ist praktisch schon möglich. Wer möchte Tausende Dateien durchstöbern, um ein einfaches Wort zu finden?
Kreativität: Ich persönlich mag keine Programme, die den Nutzer ständig bevormunden. Einfache Dinge einfach gestalten muß nicht automatisch Einschränkung heißen. Unser Anspruch ist daher auch wesentlich, daß man mit der GUI kreativ werden kann, um aus eigenen Daten herauszuholen, was herauszuholen geht.
Technische Übersicht
Nachdem ich kurz die Absichten unseres Projekts umrissen habe, möchte ich ebenso das technische Fundament unseres Projekts vorstellen. Mir ist klar, daß ich die Arbeit zweier über mehrere Jahre - wenn auch nur in der Freizeit - nicht in wenigen Minuten vermitteln kann. Darum hoffe ich, daß einige Hinweise genügen, um Ihr Interesse zu wecken.
Das Design unseres Projekts entspricht dem Model-View-Controller Paradigma.
Die Strukturierung - Model - wird in unserem Szenario vollständig von der Datenbank getragen. Betonung liegt hier auf vollständig. Wir wollen sämtliche Daten, ihre Beziehungen und ihren Werdegang in der Datenbank abgebildet wissen. Gegenwärtig beschränken wir uns auf Firebird als SQL-Engine, auch wenn unser Framework andere SQL-Datenbanksysteme ebenso zuläßt. Allerdings ist eine SQL-Engine erst ab einem gewissen Feature-Niveau sinnvoll. Für das, was wir wollen, ist sqlite aus dem Spiel. Selbst MySQL und Klone sind keine guten Kandidaten, da dort adäquate Fremdschlüsselbeziehungen fehlen. Im Klartext: Firebird, Postgres und Oracle mit Sicherheit. Weitere mögliche Kandidaten sind NuoDB und MSSQL.
Wie ich schon erwähnte, wir legen Wert auf das Wesentliche: Tiny Data, Less is more. Was ist wirklich interessant an den Daten? Oder: Struktur, Struktur, Struktur! Architektur, Erweiterbarkeit: Generische Tabellenansätze.
Die zweite Säule unseres Projekts ist der in Python 3 implementierte Teil, der im Model-View-Controller Paradigma den Teil des Controllers übernimmt. Python leistet, was die Datenbank nicht leisten kann, und wofür sie auch nicht geschaffen ist, z.B. zum Auslesen von Daten aus externen Quellen. Ich denke da z.B. an E-Mails Abholen von einem IMAP-Server. Python zerlegt auch die Daten, so daß ihre Struktur von der Datenbank übernommen werden kann, z.B. Parsen einer E-Mail samt Header und Body.
Fast ein Nebenprodukt des Python-Teils sind die Wiederherstellung und Migration von Datenobjekten. Ich kann z.B. E-Mails aus einem IMAP-Server abgreifen und in eine Maildir-Struktur überführen, oder die Mails in der Datenbank, exakt so wie sie einmal waren, in ein IMAP-Konto zurück übertragen. Das ist u.a. gemeint mit Migration.
Einen dritten Aspekt, der vom Python-Teil geleistet wird, haben wir Prozeßsystem genannt. Es handelt sich um Dienste, die beliebig (auch über Netz) konfiguriert werden können, um regelmäßig oder auf Anfrage gewisse Aktionen auf der Datenbank auszuführen. Beispiel: Sie scheiben eine Mail. Diese wird von der Oberfläche in der Datenbank übertragen und dort gleich mit allen Querverweisen erfaßt (Antwort auf, Kontaktliste an wen). Ein solcher Dienst, wie eben erwähnt, liest die Mail aus der Datenbank und versendet sie via SMTP. Ein anderer Dienst schaut alle Minute auf einem IMAP-Server nach, ob es Neuzugänge gibt.
Der anzeigende Teil - View - wird von Object Pascal, genauer von Lazarus gestemmt. Die Oberfläche weiß nichts über die Daten selbst, sie fragt einzig bei der Datenbank nach und erhält Ergebnismengen, sprich Tabellen. In diesen Tabellen ist alles enthalten, was die Oberfläche für die Präsentation der Daten benötigt.
Die Oberfläche bietet weiter Möglichkeiten zur Suche und zur Filterung. Bei Bedarf löst sie Datenbank-Events aus, auf die Python-Dienste reagieren können, z.B. versende eine gerade geschriebene E-Mail.
Zusatznote:
Abschließend könnte ich mich noch endlos darüber auslassen, warum wir als Werkzeuge PSQL, Python und Pascal verwenden. Sicher nicht der 3 P’s wegen, die vielleicht unser Projekt beschrieben wie: Pretty, Private and Practical. Ich müßte Ihnen einen Bären aufbinden, wollte ich leugnen, daß dabei nicht auch gewissen Vorlieben eine Rolle spielten. Trotzdem: SQL ist seit Jahrzehnten etabliert und weitgehend standardisiert. Die verfügbaren Server sind ausgereift und können vor allem eins besser als jede andere Lösung: Mit großen Datenmengen effizient umgehen, umso besser, je besser man in solide Strukturen investiert. Python benutzen wir erst seit einigen Jahren, und in meiner persönlichen Laufbahn als Softwareentwickler ist mir noch keine Programmiersprache untergekommen, die so viel Material anbietet und so schnell zu brauchbaren Lösungen führt wie eben diese Schlange. Ich persönlich schätze auch, daß sich die Sprache nicht so sehr in Ideologien und Paragidmen verliert wie jene Sprachen, die z.B. Wert darauf legen, streng objektorientiert zu sein. Nichts gegen Objektorientrierung, doch wird diese zur Qual, wenn man statt print("Hello World") erst einen Namespace öffnen, dann eine Instanz anlegen muß, bevor man eine Zeile ausgeben kann. Genug dazu! Pascal? Klar, damit haben wir beide Erfahrungen, zumeist positive, gerade wegen seiner Stringenz. Object Pascal und Lazarus sind zudem von der Plattform unabhängig, und Lazarus (gewissermaßen aus Delphi heraus geboren) wohl der immer noch am besten funktionierende GUI-Designer.
DB — PSQL, Modell #1

Ich wiederhole noch einmal, denn das ist wichtig und auch einzigartig: Unser Konzept beruht darauf, daß die Datenbank die gesamte Logik der Daten, ihre Beziehungen untereinander und ihre Abläufe enthält, verwaltet und ausliefern kann. Wir nennen diesen Teil die Geschäftslogik. Wenn ich mit einer GUI auf die Datenbank zugreife, so werden die Ergebnismengen, die eine Anfrage an die Datenbank liefert, alle benötigten Beziehungen für die Darstellung enthalten.
Im Vergleich dazu: Überwiegend setzen Datenbankanwendungen eine Zwischenschicht ein, die als Vermittler zwischen Datenbank und Oberfläche dient. Die Datenbanken spielen dabei nur die passive Rolle eines Containers, die Geschäftslogik ist in die Middleware eingepflanzt.
Wir bedienen uns bei der Realisierung fortgeschrittener Techniken von SQL-Datenbanken. Wenn Sie einen Blick auf das Schema werfen, beruht unser Konzept auf mehreren Schichten schon in der Datenbank. Die untere enthält die Tabellen mit primary (pk) and foreign keys (fk), mit Contraints (uc) und Indizes (index). Trigger (triggers) setzen wir z.B. ein, um Standardspalten, die jede Tabelle enthält, zu füllen. Dazu gehören zum Beispiel Zeitstempel, Name dessen, wer die letzte Aktion ausgeführt hat, ein globaler Zeilenzähler. Darüber liegen Views (views) einerseits und 3 Schichten von Prozeduren andererseits. Die unterste Schicht Prozeduren (bm - base methods) nimmt unmittelbare Änderungen an den Tabellen vor, also INSERT, DELETE, UPDATE. Die oberste stellt ein Interface (ifc) für die Außenwelt her. Die mittlere (procedures) enthält den größten Teil der Logik und kann auch mehrere Tabellen gleichzeitig bedienen, falls erforderlich.
Eine stringente Rechtekontrolle verhindert SQL-Injection. Es gibt keinen unmittelbaren Zugriff auf Tabellen. Für den Nutzer sind nach außen lediglich Views und Prozeduren der ifc Ebene sichtbar.
DB — PSQL, Modell #2
Das soll genug sein zum Schema unseres Datenbankkonzepts. Ich möchte einige Probleme aufführen, die wir an der Datenbank bereits implementiert haben oder noch realisieren wollen.
Hashes: Ich habe es schon angedeutet, wir wollen Datenobjekte eindeutig identifizieren und verwenden dafür Hashes. In einer Tabelle werden alle Hashes erfaßt. Welcher Algorithmus dabei verwendet wird, spielt keine Rolle. Eine weitere Tabelle nimmt alle Objekte als Blobs auf. Über die Hashes stellen wir sicher, das kein Objekt redundant gespeichert wird. Es gibt noch eine dritte Tabelle, die Blobs und Hashes verbindet bzw. Informationen wie den MIME-Typ verwaltet. Diese dritte Tabelle sorgt auch dafür, daß ein von der Datenbank identifiziertes Datenobjekt nicht unbedingt als Blob in der Datenbank vorliegen muß. Stellen Sie sich vor, Sie wollen ihre Videos verwalten. Wer will die alle in die Datenbank schreiben? Es reicht, die Hashes zu erfassen. Erfreulich dabei ist auch, Sie können mit dem Hash später noch feststellen, ob Ihre Videodatei noch die gleiche ist. Ich denke dabei wieder an die sogenannten “Bitrots”, also spontane Veränderungen auf magnetischen Datenträgern. Ich habe zu diesen Thema auch einen Artikel verlinkt, weil das Thema aufgrund der immer üppigeren Festplatten spürbar wird.
Hierarchien: Ein weiterer wichtiger Aspekt, der uns im Umgang mit Daten immer wieder begegnet, sind Hierarchien. Das kann der Ort eines Dokuments im Dateisystem sein, eine Maildir-Struktur, ein IMAP-Ordnersystem, ein System für Tagging. Sie wollen ein Dokument in unterschiedlich gearteten Hierarchien speichern? Nur zu! Sie wollen ein Dokument an unterschiedlichen Stellen im Baum haben? Auch das ist denkbar. Einmal erfaßt, können Sie das eingelesene Dateisystem auch wiederherstellen.
Sammlungen: Der Klassiker von Uraltdatenbanken aus dBase-Zeiten: Sie haben eine Sammlung von gleichen Dingen, seien es z.B. Bücher. Mit einem Satz von gerade einmal 4 Tabellen können wir jede Art von Sammlung, auch welche, wo alle Eigenschaften vom Benutzer definiert werden, erfassen. Als Beispiele haben wir eine Bücherverwaltung implementiert, daran hatte ich ein persönliches Interesse. Rudimentär auch Verwaltungen von Musik, Bildern und Videos; dazu aber noch ein paar Worte später! Noch einmal: Wenn Sie es wollen, können Sie hiermit auch Ihre Briefmarken, Ihre Spirituosensammlung, Ihre Oldtimer, Ihre Yachten verwalten.
Kommunikation, Kontakte: Wenn es um persönliche Daten geht, werden viele zunächst an Kommunikation und die eigenen Kontakte denken. Erfassen können wir sehr detailliert schon E-Mails, in Ansätzen auch RSS-Feeds und XMPP-Nachrichten. Wir können Kontakte aus vCards erfassen, ebenso aus E-Mail Headern. Und das ist erst der Anfang.
Dokumente, Notizen: Ein weiteres Standbein ist die Erfassung von Dokumenten im Sinne von Dateien sowie Notizen im weiten Sinne. Das heißt, wir wollen nicht nur Textnotizen zusammentragen, auch Screenshots, Schnappschüsse, Sprachnotizen ohne eine konkrete Datei mit Namen und Ordner erzeugen zu wollen.
Mit Quellenverwaltung meine ich einen Mechanismus, der sich merkt, woher alle Daten gekommen sind. Damit können wir bei Bedarf die Daten, so wie sie eingelesen wurden, wiederherstellen. Beispiel auch hier: IMAP-Server. Alle von einem IMAP-Konto eingelesenen Mails können an dieses Konto zurückgegeben werden.
Was liegt uns unmittelbar noch am Herzen?
GTD: Getting things done Wie ich die Dinge geregelt kriege. Das Modul beabsichtigt eine Arbeitsweise, wie sie vom Buchautor David Allen vorgeschlagen wurde. Das ist eine Organisationshilfe, die vor allem von Managern geschätzt wird, da sie den Fokus auf Weniges lenkt, dennoch den Überblick über Vieles wahrt.
Kalendarik: Das brauche ich nicht weiter zu kommentieren, daß man auch seine Termine im Überblick behalten kann.
Issue Tracking, oder Bugtracking im weiten Sinne. Oder simpel: Ein Ticketsystem. Das ist ein wunderbares Beispiel dafür, wie alle Dinge, die ich genannt habe, ganz natürlich miteinander verwoben sind. Ein paar Anregungen dazu: Sie entwickeln beruflich und bekommen eine E-Mail von einem Kunden mit einer Fehlermeldung. Jetzt fangen Sie an, den Inhalt der E-Mail samt Attachments in Ihren Bugtracker zu importieren. Warum nicht mit nur einem Klick? Im Sinne GTD landet jede neue Mail zuerst im Eingangskorb. Sie schauen Sie sich an. Sie klassifizieren sie als Fehlermeldung. Der Betreff der E-Mail ist automatisch die Kurzbeschreibung, der Text der primäre Inhalt, Attachments werden zu angehängten Dateien der Fehlermeldung. Vielleicht schwebt Ihnen vor, noch eine Notiz anzuheften und einen Termin zu benennen, bis wann das geklärt sein muß, und fertig! GTD erinnert Sie daran, wenn die Zeit reif ist. Und wenn Sie das Problem behoben haben, wissen Sie anhand der verknüpften E-Mail gleich, wer sich zuerst dafür interessiert. Sie sehen, Daten sind ganz naturgemäß nichts, was man beliebig zerlegen und verunabhängigen kann. Ich benutze bewußt dieses garstige Wort, um zu verdeutlichen, wie unsinnig es eigentlich ist, Daten nur getrennt zu betrachten! Es ist unser Anspruch, jene Verbindungen, die ganz natürlich sind, auch sichtbar und schnell greifbar zu machen. Dazu dient vorrangig das Konzept der Entitäten.
PM — Python, Controller #1
Der Name des zweiten Standbeins, welches auf Python 3 basiert, ist PM und steht für Process Manager. Wie ich oben bereits erwähnte, es handelt sich um netzwerktransparente Dienste, die beliebige Aufgaben für die Datenbank erledigen können. Beispiele abermals: E-Mails eines IMAP-Kontos abräumen, RSS-Feeds lesen, Messenger-Nachrichten abfangen, geschriebene E-Mails versenden. Alles, was die Datenbank selbst nicht vermag, erledigt PM für sie.
Die Dienste kann man sich wie an die Datenbank angeflanscht denken. Sie reagieren auf Ereignisse in der Datenbank oder füttern sie regelmäßig. Datenbanksysteme sind naturgemäß passiv, d.h. sie müssen gefüllt und abgefragt werden. Von allein machen sie nichts. Die PM-Dienste verleihen der Datenbank Flügel, sie wird dadurch aus Sicht des Nutzers ein aktives System.
Netzwerktransparenz meint hier: In Python implementierte Objekte können mit Python selbst (pickle, kwargs) bzw. mit JSON serialisiert werden. Als Serialisierungen gehen sie über Netz, werden remote deserialisiert und neu instanziiert. Dort erfüllen sie dann ihre eigentliche Aufgabe.
Für die Konfiguration haben wir uns zunächst für das *.ini Format entschieden, weil es für Menschen gut lesbar ist. XML und JSON sind zwar sehr flexibel; aber mal ehrlich: Wollen Sie das immer wieder lesen? Zunächst meint hier: Künftig wollen wir die Konfiguration ebenfalls in die Datenbank integrieren. Die Konfigurationsdateien enthalten dann nur noch das, was für den Start des Systems überhaupt nötig ist.
Übrigens, alle Einstellungen in einer Konfigurationsdatei sind als Standards zu verstehen und können über die Kommandozeile geändert werden. Dafür haben wir uns eine universelle Substitutionssyntax ausgedacht.
Unser Konzept beruht auf vielen kleinen Bausteinen und setzt von Grund auf Modularisierung. Es bedient sich häufig der Polymorphie, einem Basiskonzept aus der Objektorientierung. Ich werde in der Folge ein paar konkrete herausgreifen, um eine Vorstellung zu vermitteln.
db (Databases): Die unter diesem Kürzel zusammengefaßte Funktionalität enthält Datenbanktreiber mit Low Level Funktionen für ein konkretes RDBMS, z.B. Firebird, Postgres. Gemeint sind hier: Verbindungsauf- und -abbau, Senden von Requests, Einlesen und Navigation in Ergebnismengen. Hierunter zählen auch das Erstellen einer Datenbank sowie Backup und Restore.
data (Data): In diese Kategorie gehören konkrete Datenobjekte mit allen Eigenschaften, die gemäß unserem Motto Tiny Data für wichtig erachtet werden. Beispiele für solche Objekte sind eine Notiz, ein Buch, eine Dokumentendatei, eine E-Mail, ein Kontakt, eine Fehlermeldung, wenn man einen Bugtracker betreibt.
src (Sources): Sources beschreiben externe, also nicht zur Datenbank gehörende Datenquellen, z.B. ein IMAP-Konto, den Zugriff auf die Deutsche Nationalbibliothek, ein Konto auf einem XMPP-Server. Sources liefern als Ergebnis immer Objekte zurück, die in data definiert sind.
iface (Interfaces): Funktionen aus dieser Kategorie schreiben Datenobjekte in die Datenbank oder holen sie wieder heraus. Sie benutzen dabei ebenfalls die in data definierten Strukturen.
job (Jobs): Jobs stellen den aktiven Teil von PM. Sie erledigen Aufgaben aller Art. Wie das genau aussieht und wie sie dabei die anderen eben genannten Teile verwenden, werde ich jetzt anhand einiger konkreter Jobs veranschaulichen.
PM — Python, Controller #2
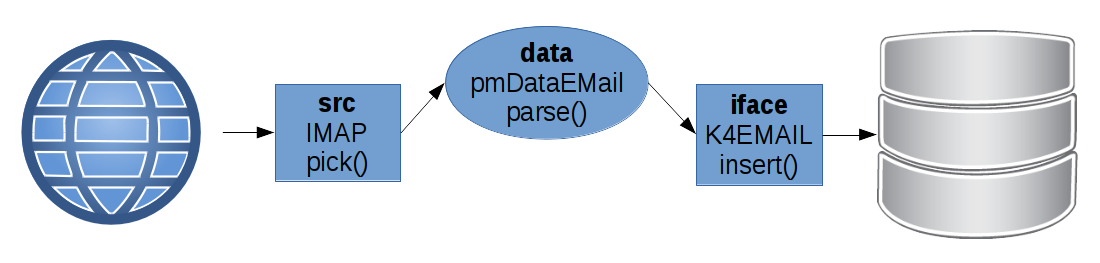
Der in Job hat die Aufgabe, eine beliebige externe Quelle regelmäßig nach neuen Daten abzustauben und diese in die Datenbank einzutragen. Wie geht er dabei vor?
Links sehen Sie die Weltkugel als Symbolum für eine externe Datenquelle.
Mit einem Modul src, einer Source - als Beispiel habe ich einen IMAP-Server angeführt - wird die externe Quelle abgefragt. Dazu ruft der Job die Routine pick() der Source auf. Für die Python affinen unter Ihnen, pick() ist ein Generator, der im Falle einer IMAP-Source eine E-Mail nach der anderen ausspuckt, die in einem IMAP-Konto neu hinzugekommen sind.
Die IMAP-Source weiß natürlich, daß sie es mit E-Mails zu tun hat und benutzt die parse() Funktion des E-Mail Datenobjekts, hier als pmDataEMail betitelt. Als Ergebnis liefert die IMAP-Source also zerlegte E-Mails als pmDataEMail Objekte aus der data Kategorie.
Das E-Mail Objekt wird an ein Interface (siehe iface Kategorie) namens K4EMAIL übergeben. Das heißt, der Job ruft für jede E-Mail die insert() Funktion des Interfaces auf. Das Interface K4EMAIL erwartet ein pmDataEMail Objekt und ruft die entsprechenden Datenbank PSQL-Prozeduren auf, um die E-Mail mit all ihren Eigenschaften in die K4-Datenbank einzutragen.
Das Interface sorgt mit Commit auch dafür, daß jede E-Mail nur als Ganzes in der Datenbank landet. Geht ein Teil schief, wird alles zurückgerollt. Abschließend ruft K4EMAIL (das ist im Schema nicht zu sehen) noch eine Finalize-Funktion der Datenbank auf, die neu hinzugewonnene Absender und Empfänger aus der E-Mail in die Kontaktverwaltung übernehmen.
Einen solchen Einlesezyklus können Sie auch auf der Kommandozeile starten mit:
./pm.py exec -C etc/k4-share.ini --job in --src IMAP --iface K4EMAIL
Aktionen von PM werden auf der Kommandozeile immer mit pm.py begonnen. Der erste Parameter konkretisiert das Kommando: exec führt einen Job aus. Die Konfiguration wird mit -C übergeben. Der Job ist in, wie es der optionale Parameter --job festlegt. Die Parameter --src und --iface legen fest, welche Source und welches Interface der Job verwenden soll, um Daten aus einer externen Quelle in die Datenbank zu befördern. Alle mit -- beginnenden Optionen sind Substitutionen (wie vorne erwähnt). Im übrigen habe ich die Beispieldatenbank mit etwa einem Dutzend genau solcher Kommandos erzeugt.
PM — Python, Controller #3

Jetzt stellen wir uns das Schema einmal umgekehrt vor. Eine E-Mail oder mehrere aus der Datenbank sollen nach außen; in unserem Beispiel in eine MBOX-Datei gespeichert werden.
In diesem Fall ruft der out Job den extract() Generator des K4EMAIL Interfaces auf, um alle E-Mails, die ein gewisses Kriterium erfüllen (z.B. aus einer bestimmten Quelle stammen) aus der Datenbank auszulesen. Als Ergebnis liefert die Funktion pmDataEMail Objekte.
Der Job übergibt die Objekte der Source, in diesem Falle eine MBOX-Source.
Die Source benutzt die restore() Funktion des Datenobjekts, um aus den Einzelheiten des pmDataEMail Objekts die Original E-Mail wiederherzustellen. Anschließend schreibt die Funktion put() der Source die E-Mail in die MBOX-Datei.
Anstelle der MBOX-Source können Sie sich auch einen SMTP-Client vorstellen, der eine frisch angelegte E-Mail versendet, oder auch ein IMAP-Konto, wohin E-Mail synchronisiert werden soll.
Das Auslesen können Sie auf der Kommandozeile starten mit:
./pm.py exec -C etc/k4-share.ini --job out --src MBOX --iface K4EMAIL
Hinweis: In dieser Form liest der Befehl nur E-Mails aus der Datenbank, die über die gleiche Source MBOX eingelesen worden sind. Er eignet sich also zur Wiederherstellung von E-Mails in ihrer Originalform in der Originalquelle.
Zusatznote:
Die beiden Jobs in und out regeln fast den gesamten Ein- und Ausgangsverkehr in die und aus der Datenbank. Sie definieren unterschiedliche Jobs in und out mit unterschiedlichen Sources und Interfaces, um unterschiedliche Datenobjekte aufzunehmen oder wieder in eine externe Quelle zurückzuschreiben. Zur E-Mail sei erwähnt: Wir haben Wert darauf gelegt, daß unser System E-Mails aus der Datenbank kryptrographisch identisch wiederherstellen kann, ohne die gesamten E-Mails als Blobs und die Anhänge extra zu speichern. Gespeichert wird tatsächlich nur ein Rumpf der E-Mail, die Anhänge dekodiert nur einmal, und restore() kann daraus das Original wiederherstellen. Das macht unsere Datenbanklösung auch als gesetzkonformes und zugleich speichersparendes Backup geeignet. Vielleicht erinnert sich der eine oder andere: Vor wenigen Jahren forderte der Gesetzgeber eine Sicherung aller E-Mail quasi im Originalzustand.
PM — Python, Controller #4
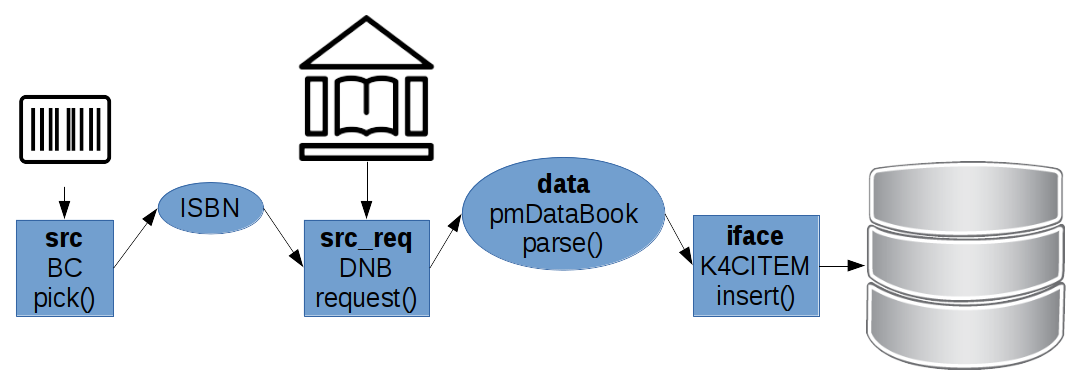
Als dritten und letzten Job möchte ich noch ssi vorstellen. Die Buchstaben ssi stehen für Source, Source, Interface. Daten werden also über zwei Sources generiert und über ein Interface in die Datenbank geschoben.
Die erste Source mit Namen BC ist ein Barcode Scanner. Der erfaßt die ISBN eines Buches; bei den meisten Büchern ist heute einer aufgedruckt.
Mit der ISBN stellt der Job einen request() an die Deutsche Nationalbibliothek. Auch hier: request() ist ein Generator, der alle Ergebnisse zur ISBN Abfrage liefert, in der Regel ist das nur ein Buch.
Das Datenobjekt ist ein pmDataBook Objekt, ebenfalls mit einer parse() Funktion ausgestattet, die sogenannte MARC21-Records lesen kann. Zur Information ohne nähere Erläuterung: Das ist ein Standardformat für bibliographische Daten.
Das Interface, das mit Büchern umgehen und in die Datenbank schreiben kann, ist K4CITEM. Der Name klingt vielleicht verwunderlich, ist es aber nicht. Bücher werden als Sammlungsobjekte verwaltet, oder auch als Collection Items. Das Interface kann alle Arten von Collection Items behandeln, Bücher sind nur ein Beispiel davon, bzw. eine Ableitung von pmDataCItem Objekten.
Die Kommandozeile dazu lautet:
./pm.py exec -C etc/k4-share.ini --job ssi --src BC --src_req DNB --iface K4CITEM
PM — Python, Controller #5
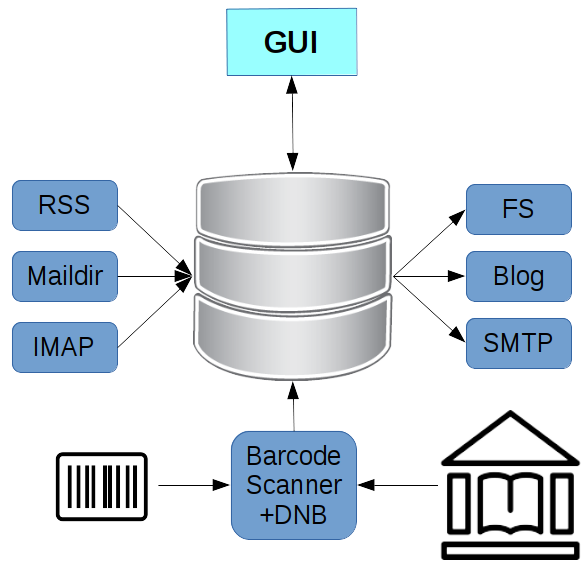
Auf dieser Seite sehen Sie schematisch mehrere Ein- und Ausgänge an der Datenbank. Als Eingänge habe ich als Beispiel IMAP, Maildir, RSS; als Ausgänge SMTP, ein Blog oder FS (für File System) gewählt. Auch hier möchte ich wieder ein paar gedankliche Beispiele geben.
E-Mail Empfang via IMAP und Versand via SMTP habe ich oft genug erwähnt.
Sie abonnieren das RSS-Feed eines öffentlichen Blogs. Regelmäßig werden dort Artikel gepostet, die unser System automatisch mit einem periodisch laufenden in Job (polling) erfaßt und verlinkt. Sie schreiben ebenfalls einen Kurzartikel. Er wird zunächst in Ihren persönlichen Daten abgelegt, anschließend über einen out Job an das Blog übermittelt.
Sie kaufen ein neues Buch und wollen es in der Datenbank erfassen. Der Barcodescanner ist immer angeschlossen. Sie scannen den Code, fertig. Den Rest erledigt der ssi Job im Hintergrund, er fragt die Nationalbibliothek ab - von mir aus auch Amazon - und speichert die Daten samt Coverbild in der Datenbank.
GUI — Pascal, View #1
Wie ich schon erwähnte, die Oberfläche für unser Projekt ist in Lazarus/Object Pascal implementiert.
Ebenso angedeutet habe ich auch, daß die GUI nichts über die Daten und ihre inneren Zusammenhänge weiß; das alles erfährt sie aus der Datenbank. Ihr obliegt es einzig, die Daten in ansprechender und aufgeräumter Form anzuzeigen und mit dem Benutzer zu interagieren.
Bisher greift die Oberfläche auf die Daten lediglich über eine direkte Verbindung zum Datenbanksystem zu. Dabei nutzt sie, wie im Abschnitt über die Datenbank besprochen, ausschließlich Views und Prozeduren aus den Schichten views und ifc. Wenn der Benutzer über die GUI eine Aktion in PM auslösen möchte, z.B. E-Mails abholen, RSS-Feeds auslesen etc., dann werden Datenbank-Events mit Hilfe einer PSQL-Prozedur ausgelöst.
Ein paar Worte zu den Konzepten, welche die Fundamente der GUI bilden:
Applics/Forms: Das erste Konzept stellt eine Funktionsaufteilung im Applics und Forms dar. Applic lehnt sich an den Begriff “Application” an und meint ein Modul mit einem konkreten Funktionsumfang. Beispiel: Eine Applic ermöglicht den Umgang mit E-Mails, eine andere den Umgang mit Dokumenten. Applics können Sie in der aktuellen Implementierung auch im Hauptmenü erkennen; viele der Menüpunkte sind Applics. Forms sind eine weitere Unterteilung in einzelne Formulare. Darunter verstehen wir Eingabemasken, Masken zur Präsentation von Daten, was im einfachsten Fall Tabellen sein können. Im Hauptmenü tauchen die Forms als Unterpunkte der Applics auf, mit anderen Worten in der Programm-Hierarchie sind Applics die Teile des Gesamtprogramms, die Forms Teile der Applics. Forms werden, wenn man sie über das Menü auswählt, in den Rahmen des Hauptprogramms hinein gelegt und angezeigt.
Applics und Forms bilden also das modulare Grundgerüst der GUI und sind vollständig konfigurierbar, z.Z über JSON-Dateien, später auch über die Datenbank. In diesen Dateien wird das Design der Forms beschrieben, indem Wigdets wie Memos, Comboboxen, Editierfelder platziert werden. Diese Widgets beziehen ihre Daten jedoch aus der Datenbank und nutzen dazu sogenannte Adapter als Datenquelle.
Adapter: Ein Adapter - diese werden ebenfalls mit JSON konfiguriert - ist nichts anderes als eine Datenbank-Query und eine Beschreibung der erwarteten Ergebnismenge. Inzwischen haben sich lediglich 3 verschiedene Arten von Ergebnismengen ergeben:
- Tabelle: Jede Zeile ist ein Objekt, die Spalten sind Eigenschaften (z.B. eine Liste von Dokumenten)
- Tabelle: Jede Zeile beschreibt eine Eigenschaft eines Objekts (z.B. alle Angaben über ein Buch)
- Blobs für Binärdaten oder größere Texte (z.B. E-Mail Anhänge, Sprachnachrichten)
HTML Rendering: Wer von Ihnen schon mit Widgets zu tun hatte, weiß wie aufwendig das ohne einen Designer ist. Die JSON-Dateien, die das Aussehen der Forms definieren, sind entsprechend lang, ihre Pflege mühsam. Deshalb haben wir uns im Laufe der Zeit auch über alternative oder auch ergänzende Wege Gedanken gemacht. Am Beispiel von Sammlungselementen wie Büchern können Sie sich das schon ansehen, die Eigenschaften eines Buchs werden nicht nur in einer Widget-Maske angezeigt, sondern auch als HTML ausgegeben und über ein rudimentäres Browser-Widget gerendert. Das Ergebnis sieht noch sehr bescheiden aus. Mit einer geeigneten Browser-Engine kann man sich hier moderne Wege der Webprogrammierung, also HTML5, CSS und JavaScript zunutze machen.
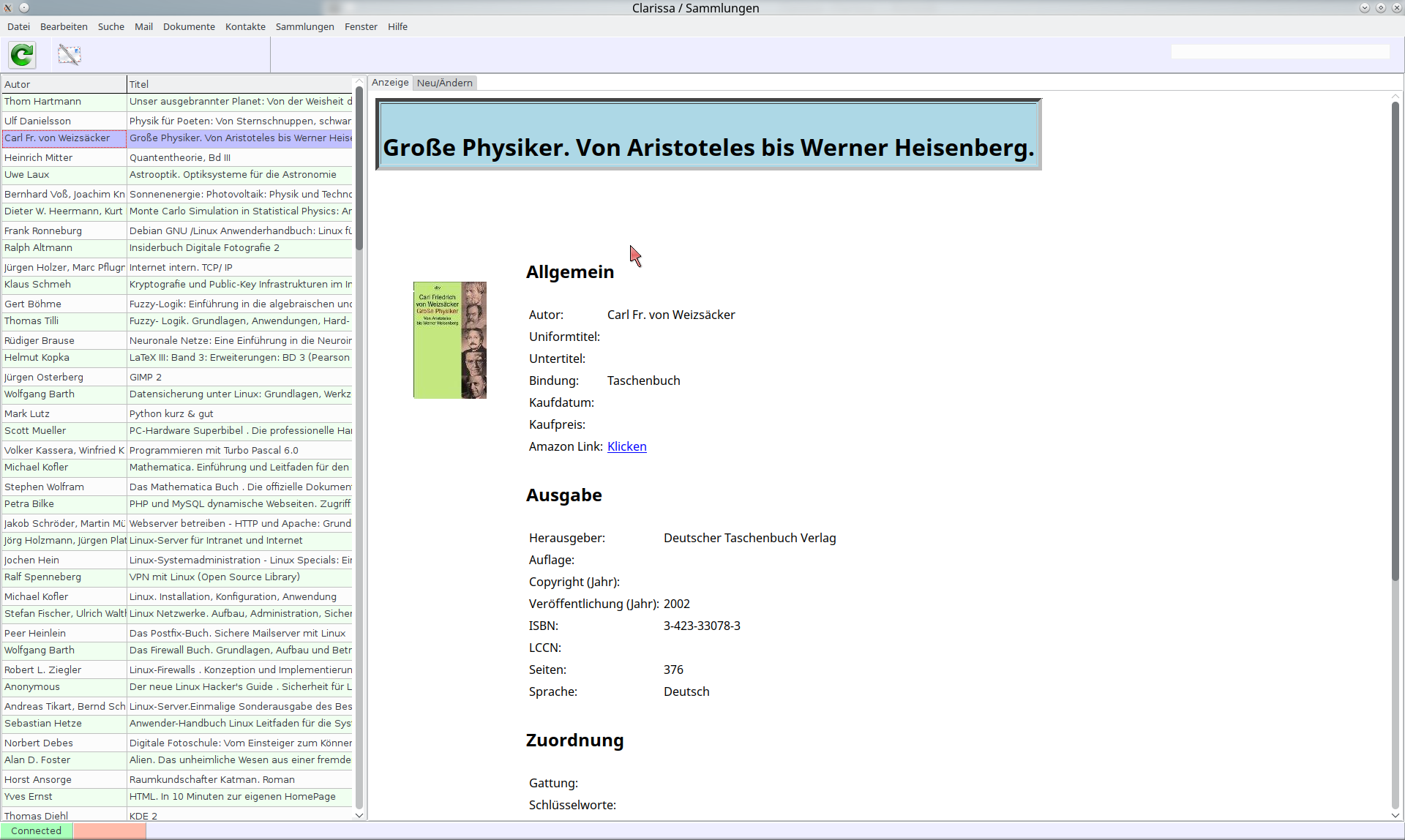
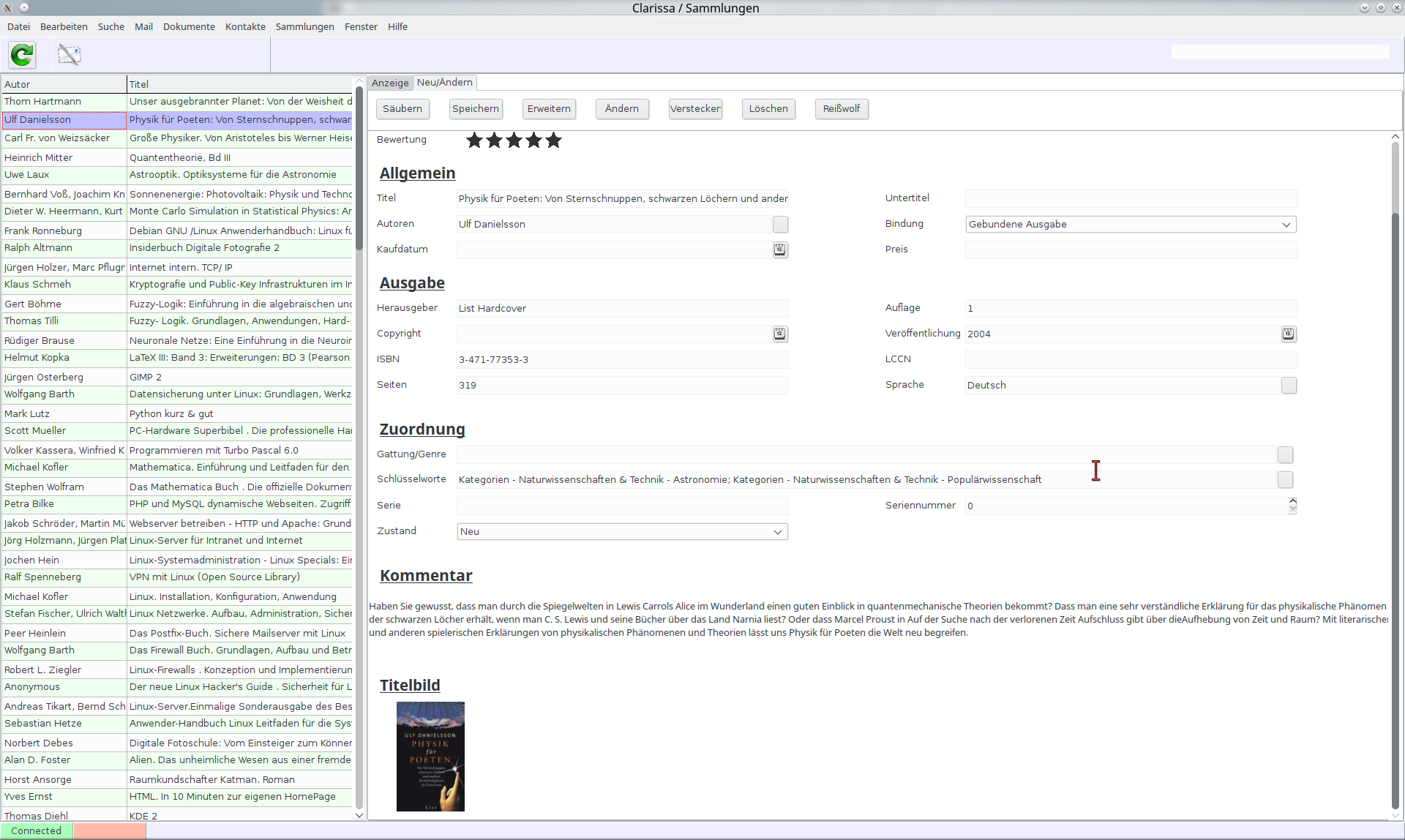
Clarissa: Noch ein paar Worte zum Namen der GUI, Clarissa: Der Name soll einen bestimmten Charakter repräsentieren. Wir verstehen unser Programm - insbesondere das, was der Benutzer sieht - nicht nur als eine Ansammlung von Masken, die in kühler Weise Daten anzeigen und entgegen nehmen. Wir verstehen unsere Oberfläche als eine Assistentin, die überall dort unterstützt, wo es angebracht ist. Sie kennen sicher alle die immer wieder aufklappenden Hinweisfenster und Sprechblasen, schlimmer noch die DSGVO-Warnungen oder Werbungen auf allen möglichen Webseiten, die in ihrer Penetranz auch jeden ruhigen Geist zur Weißglut treiben können. Ich bin sicher, das geht entschieden höflicher und auch persönlicher. Ideen dazu haben wir reichlich. Doch bevor wir den Chrom polieren, sollte der Unterbau auf solidem Grund stehen.
GUI — Pascal, View #2
Routing: Noch nicht erläutert habe ich das Konzept des Routers innerhalb von Clarissa. Sie wissen, die GUI weiß selbst nichts über die Art der Daten. Auch alle Masken werden per JSON konfiguriert. Das heißt aber auch, Sie müssen auch die Interaktionen zwischen den GUI-Komponenten konfigurieren. In der Sprache der objektorientierten Programmierung: Sie müssen Events und Eventhandling über die Konfiguration verknüpfen. Das möchte ich nun anhand der folgenden Graphik beschreiben.
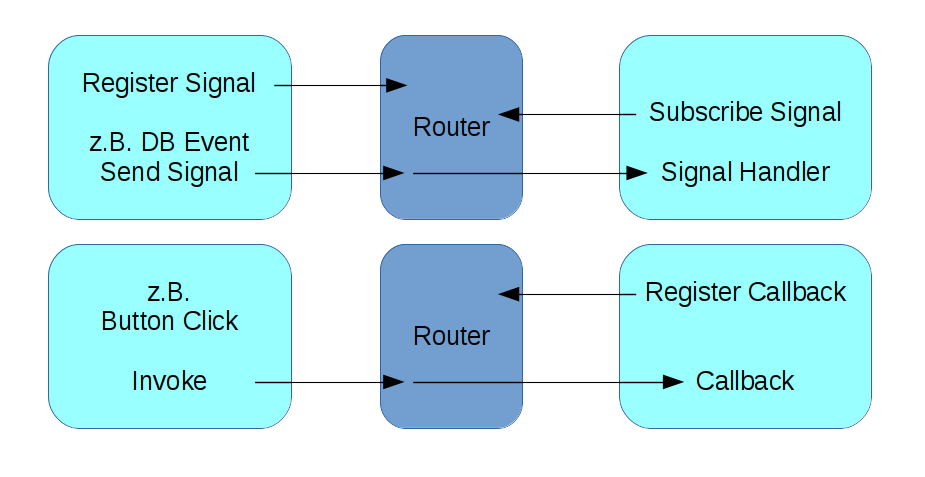
Das Herzstück des Mechanismus ist ein Router, der diverse Funktionen zum Austausch von Nachrichten anbietet. Die beiden unterschiedliche Szenarien des Austauschs sind abgebildet.
Das erste Szenario ist ein klassischer publish subscribe Mechanismus. Eine Komponente, z.B. eine Datenbankanbindung registriert beim Router ein Signal unter einem bestimmten Namen (publish). Das kann zum Beispiel ein Datenbank-Event sein. Eine andere Komponente meldet sich für dieses Signal an (subscribe). Das Event der Datenbank trifft ein, das Signal wird ausgelöst. Der Router verteilt es an alle Komponenten, die sich dafür angemeldet haben. Diese Komponenten führen in Reaktion darauf eine Behandlungsroutine aus.
Das zweite Szenario erinnert an remote procedure call. Hier meldet eine Komponente eine Routine beim Router unter einem bestimmten Namen an (register). Eine andere Komponente, im Beispiel ein Button, der geklickt wurde, ruft über den Router die registrierte Routine (mit bestimmten Namen) auf. Sie können sich jetzt vorstellen, daß Widget-Ereignisse wie OnClick über symbolische Namen konfigurativ miteinander verknüpft werden.
GUI — Pascal, View #3
Eingabe via sys_evt_i_anl: Sie haben jetzt in einfach überschaubarer Form verstanden, wie die GUI intern arbeitet und wie Daten aus der Datenbank an die GUI gelangen. Der umgekehrte Weg wäre noch zu klären. Das modulare Konzept der GUI basiert auf JSON, warum auch nicht der Datentransfer aus der GUI in die Datenbank?
Ich hoffe, Sie erinnern sich noch an den Job, der mit Hilfe einer ISBN Archivdaten der Deutschen Nationalbibliothek erfragt und diese als ein Sammlungsobjekt Buch in die Datenbank einträgt. Das möchte ich jetzt in etwas abgewandelter Form vorführen. Die einzelnen Schritte, die dabei ausgeführt werden, sind in der folgenden Graphik skizziert.
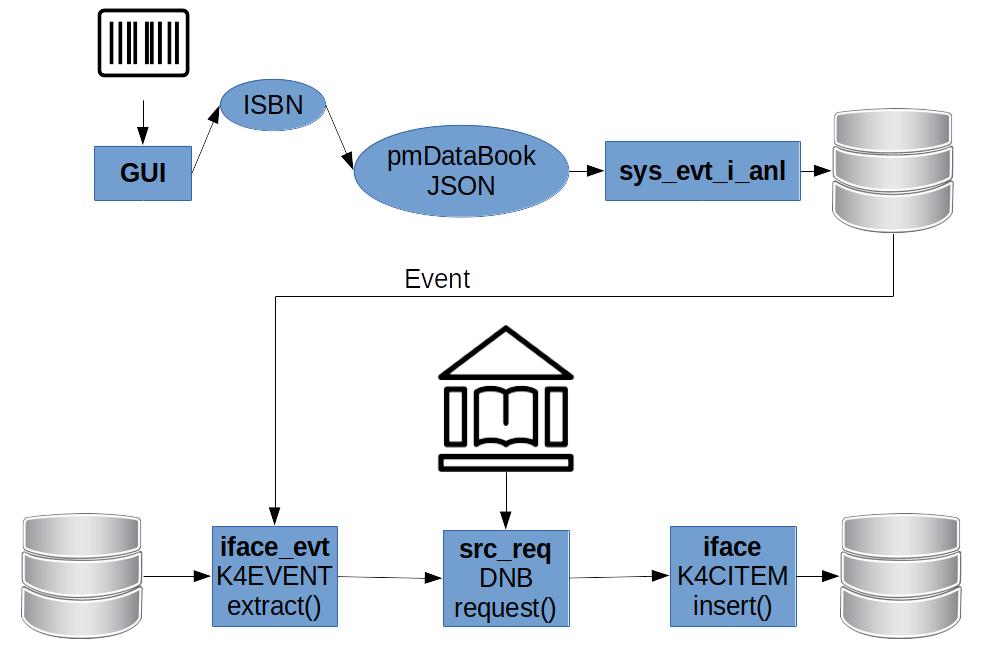
Mit einer Tastenkombination, vorläufig F9, öffnen Sie ein separates Fenster, das einzig die ISBN erfassen soll. Die können Sie jetzt auch manuell eingeben und “Erfassen” klicken oder ENTER drücken. Der Barcode Scanner macht das gleiche. Er arbeitet wie eine Tastatur, gibt die Ziffernfolge ein und löst ENTER aus.
In der Folge wird die Eingabe ausgelesen und ein JSON-Objekt generiert. Das JSON-Objekt repräsentiert ein Buch mit nur einer Eigenschaft - seiner ISBN. Das JSON-Objekt - serialisiert als Zeichenkette - wird über eine spezifische SQL-Prozedur sys_evt_i_anl in die Datenbank gespeichert. Nach dem Eintrag in die Datenbank löst die Prozedur ein Event mit einem konkreten Namen, der als Parameter an die Prozedur übergeben wird, aus.
PM lauscht auf dieses Event und führt einen Job aus, der ähnlich wie der ssi-Job das JSON-Objekt wiederum ausliest, daraus ein Buch-Objekt mit ISBN erstellt, damit eine Anfrage an die Deutsche Nationalbibliothek stellt und die Ergebnisse davon als neues Sammlungsobjekt in die Datenbank einträgt.
Der Eintrag des neuen Sammlungsobjekts löst wiederum ein Event aus, worauf die GUI reagiert und den Neuzugang auch anzeigt.
Was gibt es noch?
Bisher habe ich einige grundlegende Funktionsweisen erläutert und auch vorgeführt. Vor dem Ende möchte ich noch einen kurzen Überblick geben, womit wir uns ebenfalls beschäftigt haben. Die meisten dieser Aspekte werden künftig noch überarbeitet.
RSS-Feeds: RSS-Feeds sind seit Twitter und Co. ein wenig aus der Mode gekommen. Man kann ebenso gut auch Tweets auslesen und in den persönlichen Datenbestand aufnehmen, sei es, um Recherchen zu betreiben, oder wofür auch immer. Unser Programm möchte da keine Grenzen setzen. Im Gegenteil, das Konzept möchte neue Datenquellen möglichst schnell erschließen können.
XMPP Nachrichten und Logs: Das Thema der Kurznachrichten aller Art überhaupt - Stichwort WhatsApp - genießt auch für uns Priorität. Hat von Ihnen schon einmal jemand darüber nachgedacht, in den persönlichen Unterhaltungen über Messenger irgend etwas wiederzufinden? Ich schon!
vCards: Unser System versteht sich als eine Lösung, die möglichst viele persönliche Daten weitgehend automatisch zusammenträgt und nach überschaubaren Kriterien bewertet. Das heißt, vCards, sobald sie auftauchen, gehören ausgelesen und als Kontakte in die Datenbank gespeichert. PM macht das bereits, kommt allerdings mit manchen fehlformatierten vCards noch nicht zurecht.
Medien: Bild- und Tondateien führen oft etliche Metainformationen mit sich (Stichworte EXIF für Bilder und ID3 für Tondateien), die für eine Zuordnung und Suche wertvoll sind. Python Module, die solche Daten auslesen, gibt es reichlich, interessanter ist hier eine sinnvolle Auswahl zu treffen. Zum Beispiel Bilder mit GPS-Koordinaten - aktuelle Bildverwaltungen wie digikam zeigen bereits, was man damit anstellen kann, auch ohne die eigenen Schätze bei Google und Co. hosten zu müssen.
Extraktion von Text: Erinnern wir uns an die Suche zurück, welche ich zu Beginn vorgeführt habe. Sie können sich vorstellen, um eine solche Suche zu ermöglichen, muß man Texte aus allem, was man verwalten kann, herausholen. Unter anderem aus HTML-Dokumenten, allein schon, um HTML formatierte E-Mail durchsuchen zu können.
Tokenizer: Hat man native Texte vorliegen, müssen sie in Wortlisten zerlegt werden. Einen solchen Generator haben wir geschrieben, der neben der Zerlegung auch eine grobe Klassifizierung in Zeiten, URLs, IP-Adressen und E-Mail Adressen vornimmt.
Zum Abschluß demonstriere ich noch einen Leckerbissen: Stellen Sie sich vor, Sie sind unterwegs und sehen etwas Amüsantes. Was werden die meisten tun? Smartphone raus und knipsen, an Freunde verschicken oder auch nicht. Manchen wird das genügen. Aber mal ehrlich, wieviele sehen sich die Bilder später noch mal an? Würde sich das ändern, wenn man das gerade aufgenommene Bild auch schnell in die eigene Datenbank bekommt? Also nicht in eine Cloud, die vom Anbieter gnadenlos ausgeschlachtet wird?
Ich habe dazu ein Experiment mit einem Telegram Bot vorbereitet. Für alle, die das zum ersten Mal hören: Telegram ist im Grunde wie WhatsApp mit dem Unterschied, daß das API offen ist und man eigene Bots erstellen kann. Mit dem kann man sich verbinden und ihm genau wie anderen Leuten Texte, Bilder, Audioaufnahmen senden. Unser Bot macht nichts anderes als die Sendungen abzugreifen und als Notiz in die Datenbank zu schreiben.
Ausblick
Ein kurzer Ausblick soll ebenfalls nicht fehlen. Ich habe an mehreren Stellen schon angemerkt, wohin wir kommen wollen. Sie haben gesehen, daß wir insbesondere noch für die GUI die Fundamente schleifen, denn ich betone es noch einmal: Grundvoraussetzung für eine effiziente Verwaltung persönlicher Daten sind eine durchdachte Strukturierung und eine solide Architektur.
Messenger, Kontaktverwaltung, Gespräche, GTD (getting things done), Kalendarik, Issue Tracking: Habe ich alle schon einmal erwähnt, der Vollständigkeit halber sind sie auch hier noch einmal aufgelistet.
Für die Suche sind Textextraktionen und Klassifikation entscheidend. Bisher extrahieren wir Texte nur aus HTML, weil es oft auch in E-Mails verwendet wird, diese läßt sich aber noch verbessern. scrapy und beautifulsoup sind Python Module, womit sich solche Aufgaben lösen lassen.
Selbstverständlich wollen wir auch Texte aus Officedokumenten und PDF extrahieren können. Auch dafür bietet Python Module an, es gilt zunächst herauszukriegen, wie gut sie wirklich sind.
Wenn man Texte zerlegt und klassifiziert, so daß sie sich für einen Suchindex eignen, kann man verschiedene Konzepte, die heute in die Sparte “KI” gehören, anwenden. Generationen von Infomatikern beschäftigen sich damit, wie man aus Texten Informationen herausziehen oder Worte auf die Wortstämme reduzieren kann. Für Python gibt es Module wie nltk (Natural Language Toolkit) und scikit-learn (Maschinelles Lernen). Das erste Modul beschäftigt sich mit natürlicher Sprache, das zweite mit Methoden des maschinellen Lernens evtl. für ein automatisiertes Tagging.
Privatsphäre ist das tragende Motiv unserer Bemühungen, Verschlüsselung ist dazu ein bekannter Weg. Doch lassen Sie mich noch einen Aspekt aus dem Leben herausgreifen: Sie melden sich bei Amazon an, haben ein Paßwort. Eventuell sind Sie bei Facebook, das ergibt noch ein Paßwort. Noch ein Versandhandel, ein Mailserver, ein XMPP-Server, und und und… Wieviele Paßwörter werden Sie genötigt, sich zu merken? Wenn Sie sich mehr als 5 - ich betone sichere - Paßwörter merken können, sind Sie wirklich gut. Was macht der Rest? Ihre Möglichkeiten: Immer das selbe, Vergessen, 012345, Aufschreiben oder über zentralisierte Dienste wie z.B. Facebook. Das alles sind Todsünden hinsichtlich der Sicherheit. Die letzte Möglichkeit: Speichern. Ja, es gibt Tools dafür. Wieder ein Extraprogramm, eigene Bedienung, eigene Konzepte. Für uns ist es lediglich eine Aufgabe für Clarissa, jener freundlichen Assistentin, die sich all diese Nebensächlichkeiten im Leben merkt und bei Bedarf ausspielt!
Wieviel Privatsphäre haben Sie in einer Cloud? Höflich ausgedrückt: Unbekannt. Wenn Sie zu Hause einen NAS stehen haben sollten, werden Sie sicherlich Ihren Grund dafür haben. Sei es, um Kontaktlisten oder Bilder zu speichern. Es wäre der ideale Ort für unsere Datenbank, wenn man einen Weg findet, den mobilen Zugriff soweit abzusichern, daß auch der NAS Anbieter mit dem Datenstrom nichts anfangen kann. Ganz klar, das gehört zum Ziel!
Ein Blick in die weitere Ferne soll auch gewagt sein: Stellen Sie sich außerdem vor, Sie tauschen Daten mit vertrauten Personen nicht mehr über einen Provider wie Facebook oder Messenger Dienste aus, sondern ausschließlich direkt. Von einer K4 Instanz zur anderen: Peer to Peer. Zu beurteilen, was das bedeutet - das überlasse ich Ihnen!
Die Liste der Ideen könnte ich noch lange fortsetzen, doch ich schließe hiermit und danke für Ihre Geduld, mir bis hier her gefolgt zu sein.
Literatur
Projekt Webseite
<www.leitstern.de/k4/index.html>
E-Mail Adresse
Literatur
“Wiki: Intelligenz” https://de.wikipedia.org/wiki/Intelligenz
“Wiki: GAIA” https://de.wikipedia.org/wiki/Gaia_(Raumsonde)
“Will 2018 see the death of printers and email in the workplace?” http://www.zdnet.com/article/will-2018-see-the-death-of-printers-and-email-how-the-us-office-will-change-in-5-years/
“Es ist was faul im E-Mail-Land: Zwischen Komplexität und ungleichen Machtverhältnissen” https://www.heise.de/newsticker/meldung/Es-ist-was-faul-im-E-Mail-Land-Zwischen-Komplexitaet-und-ungleichen-Machtverhaeltnissen-4259518.html?seite=all
“Hierarchical File Systems are Dead” https://www.eecs.harvard.edu/margo/papers/hotos09/paper.pdf
“Auch 2029 wird es keine Künstliche Intelligenz geben, die diesen Namen verdient” https://www.wired.de/article/auch-2029-wird-es-keine-kuenstliche-intelligenz-geben-die-diesen-namen-verdient
“Bitrot and atomic COWs: Inside next-gen filesystems” https://arstechnica.com/information-technology/2014/01/bitrot-and-atomic-cows-inside-next-gen-filesystems/
David Allen, “Wie ich die Dinge geregelt kriege”, Piper, 11. Aufl. 2010, 978-3-492-24060-4